
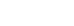

The last decade believed that Machine Learning was a speciality exclusively for the high-end technology nerds. The pioneers of technology like Google, Facebook, Amazon etc. has helped Machine Learning attain a reinforced makeover by creating a niche for it in the technology landscape. This has created a huge hype in the popularity of Machine Learning in the last few years. In fact it has become the cynosure of most of the technology enthusiasts.
“Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed. It focuses on the development of computer programs that can teach themselves to grow and change when exposed to new data.” It is always easier to think that Machine Learning is hard to learn. This is mainly due to its confusing overlapping with similar learning concepts such as Data Mining, Artificial Intelligence, Deep Learning etc. The mist has to be cleared regarding these concepts by drawing a clear distinction among them.
Most of the attempts to draw this line of distinction seemed to be too mathematical or had too much of code that took the confusion to higher levels. The need is to explain the concepts of Machine Learning and other similar concepts in simple language that anyone can understand. The July edition of FAYA:80, led by Mr. Praseed Pai of UST Global, tried to work in this direction by breaking the myths and hypes around Machine Learning.
Let me walk you through the cream points handled during the FAYA:80 on Machine Learning.
1. What exactly is Machine Learning?
2. How is it different from Data Mining and AI?
3. Teaching Machines…. But How??
4. Is there a model to teach Machines?
5. What kind of data is being dealt here?
6. What about the Machine Learning Algorithms?
7. How about the languages that can be used?
8. What are the “Grab-fast” areas of application?
9. Is Machine Learning the FUTURE??
1.What exactly is Machine Learning?
I have already provided one of its “standardised” formal definitions at the beginning of the article.
Putting it in an informal way, Machine Learning is that technology that lets machines take decisions on its own by analysing huge amounts of data. It is as simple as Google serving trillions of searches by providing results which is more specific and most relevant to the user every time. Yet another example is that of Facebook customising each user’s News Feed with the most relevant feeds rather than bombarding it with updates from everyone in the Friends List. i.e. If you “like” or “share” a particular friend’s post, the News Feed will begin showing more of that friend’s activities in the feed.
In another point of view, Machine Learning is all about automating the ‘Automation’ done by programmers.
The software programmers develop tools to automate specific tasks than coding a rule based decision making algorithm. Here, the program serves as the instruction-set that is executed by a computer. For example, Email Spam Filtering.
The programmer comes up with a Rule-set and feeds it to the machine to automate spam-filtering. Furthermore, he has to test the spam-filter with real-time data, evaluate and improve it constantly by updating or changing the rule-set.
Instead of designing the Rule-Set to automate spam filtering, the data is fed to a Machine Learning algorithm to identify the rules by itself. The data fed to the algorithm will consist of a set of spam e-mails and non-spam e-mails and the Machine Learning algorithm learns from experience to filter the spam mails. Thus it automates the Automation done by the programmer.
2. How is it different from Data Mining and AI?
Another question that haunts any newbie to Machine Learning is its difference with concepts such as Data Mining and Artificial Intelligence.
Machine Learning Vs Data Mining
Data Mining is a foundation for both Artificial Intelligence and Machine Learning. Data Mining can aggregate relevant data from huge datasets from various sources to identify hidden patterns and correlations. It can find the answers to questions that one hasn’t thought of. In simpler terms it searches for specific information while Machine Learning deals with performing a given task.
Machine Learning Vs Artificial Intelligence
ML is a subset of AI where the machine is trained to learn from past experiences that is derived from the dataset fed to it. It then uses the ML algorithms to derive the final results. AI is the field of study that simulates intelligent behaviour in machines. A machine is said to be intelligent if it can do things normally associated with human intelligence. A system powered with AI will involve a ML step wherein the system is trained to predict the best outcomes and an implementation of this trained system into a machine that mimics human intelligence.
iOS’s Siri, Android’s Google Now and Windows Mobile’s Cortana are intelligent digital personal assistants that are powered with AI. These collect data on your requests and then use that data to better recognise your speech and provide the results customised for your preferences. The machine passes through various processes such as natural language processing (to communicate with no trouble in a given language); automated reasoning (using stored information to answer questions and draw new conclusions) and machine learning (to adapt to new circumstances and detect patterns) before qualifying itself as artificially intelligent.
For example, finding the best driver in a city from the driving data of each driver is Data Mining. Making use of this data to identify and learn the best method of driving is Machine learning. Enabling a machine to use this learning to drive a car is Artificial Intelligence..
Well… Hope that makes some sense.
3. Teaching Machines…. But How??
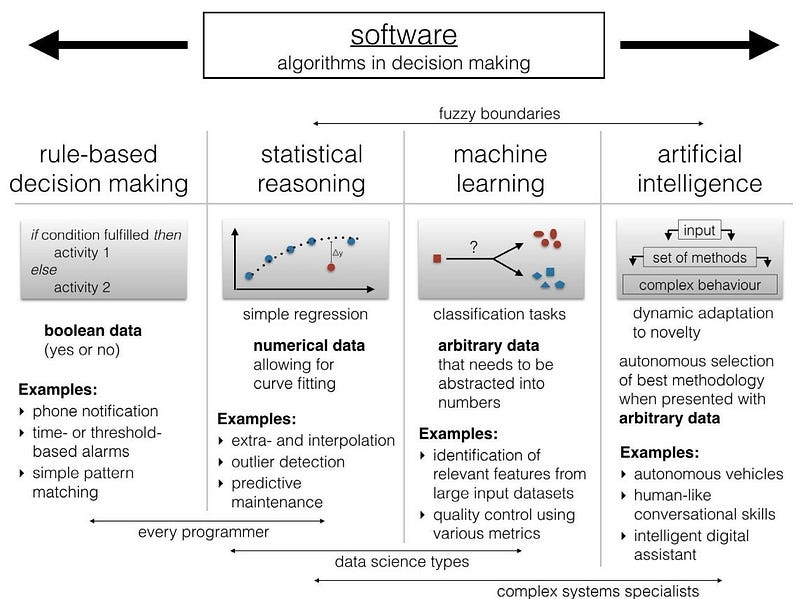
ML is all about teaching machines that works with ones and zeros alone. How is it even possible to make them learn when all they understand is just ones and zeros?? It is not as complex as you think. All we need is to follow a structural process where each phase drives the machine a step closer to deriving the conclusion.
Phase 1
Data Input: The data can be from various sources and in different formats. It can be text files, SQL databases, spreadsheets, etc. This serves as the training data for the machine.
Phase 2
Data Abstraction: This is the phase where the actual learning takes place. The ML algorithm comes into play and represents the data in a structural format by reducing it into a simpler and logical format. The algorithm chosen has a pivotal role in this process.
Phase 3
Generalisation: The learning of the machine is said to be effective only if it can be used to generalise the real-time data that will be fed to it. This phase is the closest to the practical application of the machine. The learning from the previous phase is used to derive new insights.
But how successful is the machine in learning?? It purely depends upon two elements:
The extent of generalisation of the data abstracted
The accuracy of the machine in predicting the future results based on the learning acquired.
4. Is there a model to teach Machines?
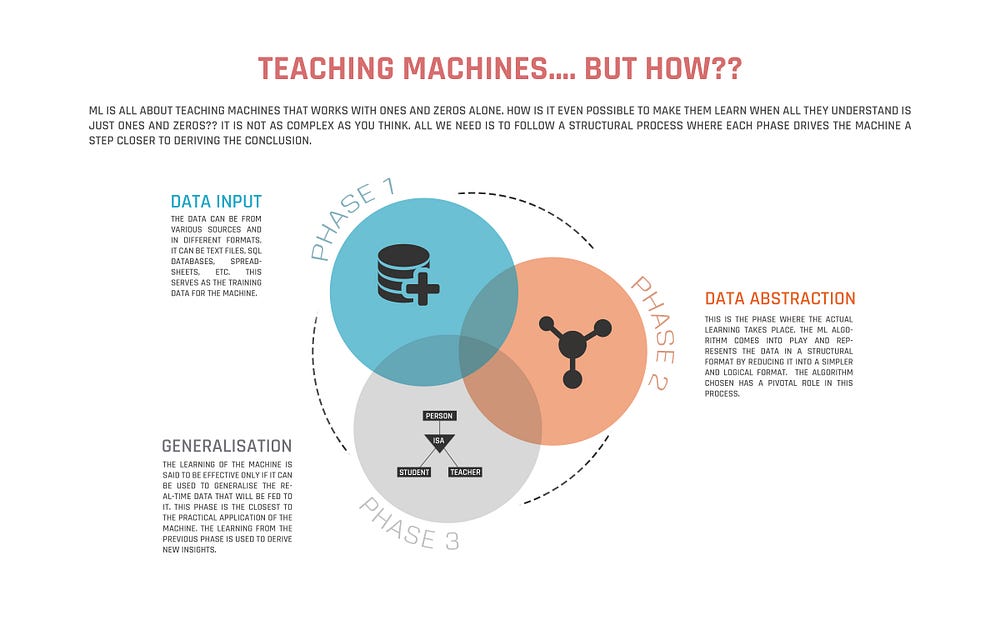
Yes, there is. The ML tasks can be generalised into five steps.
a) Data Collection: Data can be from various sources such as spreadsheets, database files, text files etc. Better the quantity and quality of data, better is the learning of the machine.
b) Data Preparation: The data under study should be eliminated from unnecessary noises and disturbances that are not of our interest. Moreover steps need to be taken for fixing issues such as missing data and treatment of outliers.
c) Training the Data Model: The appropriate algorithm is chosen in this step and the data is represented in the form of the model. The cleaned data is split into training data and testing data. The training data is used for developing the Data Model while the testing data is used to ensure that the model has been trained well to produce accurate results.
d) Data Model Evaluation: This step ensures the accuracy and precision of the algorithm chosen based on the results obtained using the test data.
e) Performance Improvement: If the accuracy of the results is not satisfactory, then a different model can be chosen to implement the same. The algorithm can also be modified by introducing more variables. All these adjustments and modifications happen in this phase.
5. What kind of data is being dealt here?
The data comes into the system from various sources and in various formats. The data can be of different types.
Nominal or Categorical: Categorically discrete data such as name of a place, type of car you drive or color of your hair belongs to this type.
Ordinal data: Data that has a natural ordering like the order of runners finishing a race. We cannot state with certainty whether the intervals between each value are equal.
Interval data: Data whose intervals between each value are equally split. E.g. Celsius — Fahrenheit Conversion
Ratio data: Interval data with a natural zero point. E.g. height and weight.
Boolean/Binary (Y/N,M/F)
The sources of data differ according to the type of application. Few sources of data according to the application are given below.
Database-oriented Applications
Relational database, data warehouse, transactional database
Advanced Applications
Data streams and sensor data
Structure data, graphs, social networks and multi-linked data
Object-relational databases
Multimedia database
Text databases etc..
6. What about the Machine Learning Algorithms?
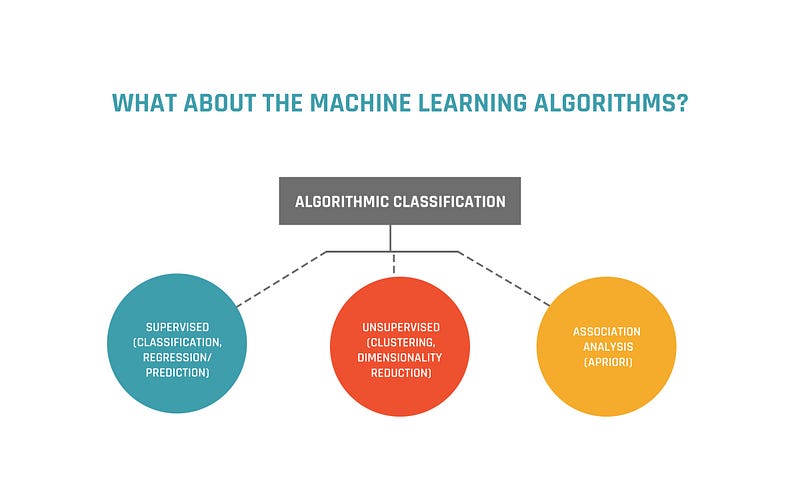
Supervised Learning:
These are predictive models that predict the future outcome based on the historical data. This kind of learning is always under the guidance as in what needs to be learnt and how it is to be learnt.
E.g.: Arranging the apples and grapes, from a basket full of fruits, on to a deck. From previous experience, you already know how to identify the fruits based on its color, shape, size, etc.
Some examples of algorithms used are: Nearest Neighbour, Naïve Bayes, Decision Trees, Regression etc.
Unsupervised learning:
These are used to train descriptive models that allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the variables.
E.g.: Arranging the apples and grapes, from a basket full of fruits, on to a deck. But this time you do not know how to identify the fruits based on its color, shape, size, etc. You try to find out similar characteristics of the fruits and arrange them accordingly.
K- means Clustering Algorithm is a common algorithm of this type.
Association Analysis:
This is the learning where ideas and experiences reinforce each other and can be linked to one another.
E.g.: Suppose a doctor over years of experience forms associations in his mind between patient characteristics and illnesses that they have. If a new patient shows up then based on this patient’s characteristics such as symptoms, family medical history, physical attributes, mental outlook, etc the doctor associates possible illness or illnesses based on what the doctor has seen before with similar patients.
Apriori Algorithm is one of the common association learning algorithms.
7. How about the languages that can be used?
The programming language for machine learning should be selected by considering the own requirements and comfort of the programmer. The languages you could choose to implement Machine Language are:
If you are a non-programmer, I highly recommend using Weka for playing with various Machine Learning Algorithms.
8. What are the “Grab-fast” areas of application?
There are a plethora of fields where Machine Learning could be applied. In fact most of the systems developed by businesses can be re-engineered the “Machine Learning” way. For e.g., if Google was created from scratch today, much of it would be learned and not coded. Companies like Google, Amazon, Accenture, Toyota, Hitachi, Tesla, Johnson & Johnson and many more have embraced machine learning at massive scale to improve their products and services.
Few areas of Machine Learning that I would like to work are:
9. Is Machine Learning the FUTURE??
Machine Learning can never replace humans. But obviously it can modify how humans look at the world. I will not say that Machine Learning is the only thing in the Future. Definitely, it has the power to capture future if channelized in the right direction with the right amount of push. It could really has the potential to change the way the world currently works.
Machine Learning is still in its early incubation phase. Developing systems based on this technology is doable now. But it requires constant effort since it is not a static piece of code. It has to be fed constantly with data and has to be reworked until the expected accuracy in results is obtained.
But yeah…various Machine Learning systems implemented by big-guns of technology like Google, Facebook, Amazon and by few start-ups are one of the clearest expressions of time-stamping the upcoming reign of Machine Learning in the future.
How to re-engineer my product around Machine Learning??
Which courses to study and blogs to follow to acquire expertise in Machine learning??
These are the basic questions that might have popped up in your minds by this time. Lets join together to crack all these questions. Join our Facebook community and do watch our technical sessions on Machine Learning .